
今年初,有感于微信公众号平台删帖效率,打算写一个自动检查文章是否被删的机器人。
并不想弄成爬虫,只想关注我和小伙伴们所接触的领域里的信息审查状况。就把它设计成了「被动接受观察目标,定期观察和备份文章,检查到文章失效通知登记者」的系统。
标签: Bot
写了一个脚本实现自动化测试过程。
最近公司在做一些测试,属于简单重复劳动,一套做下来费神费力,又学不到什么东西,几乎没有收获。
因此写了一个python脚本自动去控制整个流程。
测试的流程是在一个Terminal软件里执行一系列命令(有一定规律性),然后对输出的结果做文字处理(提取关键信息,做数据统计、分析)。
文字处理用python好做,但是数据处理过程中其实是用一个前辈写的脚本软件实现的,所以有一丢丢麻烦的地方。
最后我写了三个程序来组成这个自动化脚本。
主程序会使用PyAutoGUI库来实现对鼠标和键盘的控制。
A子程序是一个命令生成器,在它里面定义一些规律性的东西,然后生成出一个cmd_list传回主程序。调试的时候直接运行子程序就能看到是否生成了预期的系列指令。
B子程序是中间信息处理。将主程序写在input文件里的内容提取出目标数据,存入另一个文档,用os库调用前辈的.exe档来执行中间处理。
具体来说,我的PyAutoGUI在程序开始运行时会要求用户进行两次移动鼠标的操作(坐标采集)。
采集到的坐标分别对应了Terminal软件和txt文档的编辑器。
正式开始运行之后,程序调用A的生成器获取命令列表,移动鼠标到Terminal去,选中这个Terminal,然后用键盘对它输入指令(整个命令列表)。
这里存在一个判断,如果当前输入的这条指令是一个很耗时的操作,那就time.sleep(5)这样等待一段时间。否则Terminal那边执行到一半,键盘就会开始下指令。相应地,输出的log信息也就会被打乱。
完成一套测试指令之后,PyAutoGUI会执行CTRL+C,去txt编辑器那边CTRL+V,然后保存这个log文件,交给B去做数据处理。
B完成处理的分析结果我是直接print到了console里。这样我对每轮的输出可以进行检查,然后手动写入excel文档里。
不过应该用csv库直接导出到csv更好。给代码增加一点健壮性,遇到log异常的时候直接重新进行测试就好了。
用到的第三方库:
- os
- time
- pyautogui
经验性的总结:
PyAutoGUI很好用,它还有官方中文说明文档:Doc PyAutoGUI
应该将程序模块化实现。对每个子程序都可以用
if __name__ == "__main__":
单独调试,很赞。
如果程序的功能相对固定,不需要经常修改的话,可以封装成exe,这样也方便同事使用(比如前辈给我的那个exe档)。例如可以参考:如何将python程序封装成exe可执行文件
后续如果要加csv输出的功能,参考:
13.1. csv — CSV File Reading and Writing
总结python对csv文件的操作
目前还存在另一个问题就是PyAutoGUI库还没支持多屏。双屏时它对相同坐标位于哪个屏幕可能会有些困扰。所以我跑脚本时都得把外接显示器拔掉。
这个问题只能等新版本的PyAutoGUI解决了。
Telegram 为robot提供的 API
官方页面在这里:Telegram Bot API
而我使用的是一个叫 python-telegram-bot 的第三方库:https://github.com/python-telegram-bot/python-telegram-bot
开始用之前,你需要在telegram上找到@BotFather,根据它的指示新建一个机器人。完成之后你会得到一条这样的消息:
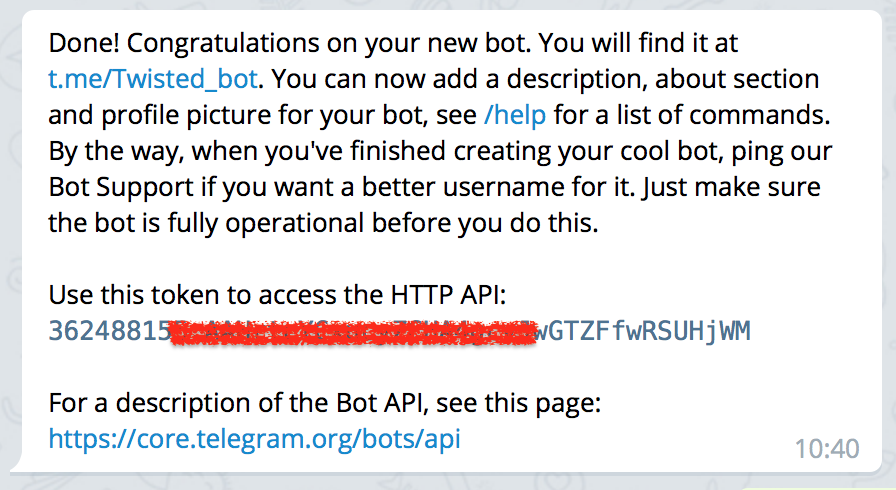
被我码掉的部分才是你需要的东西,也就是这个机器人的token。
这个第三方库通过 Updater 来基于token监听机器人的变化(接收到的信息)
from telegram.ext import Updater
updater = Updater(token='TOKEN')然后用 Dispatcher 对它做出响应
dispatcher = updater.dispatcher具体的做法是,建立一个handler,对特定的命令执行相应的函数:
from telegram.ext import CommandHandler
start_handler = CommandHandler('start', start)
dispatcher.add_handler(start_handler)上面的例子里,事先已经写好了一个start函数,(telegram里面大多数机器人都有 /start 命令)
当用户向机器人发送 /start 的时候,dispatcher 对’start’句柄调用start函数,传入 def start(bot, update) 的两个参数分别是 telegram.bot.Bot类 和 telegram.update.Update类。
我在函数内部执行以下代码:
print bot
print type(bot)
print update
print type(update)输出是:
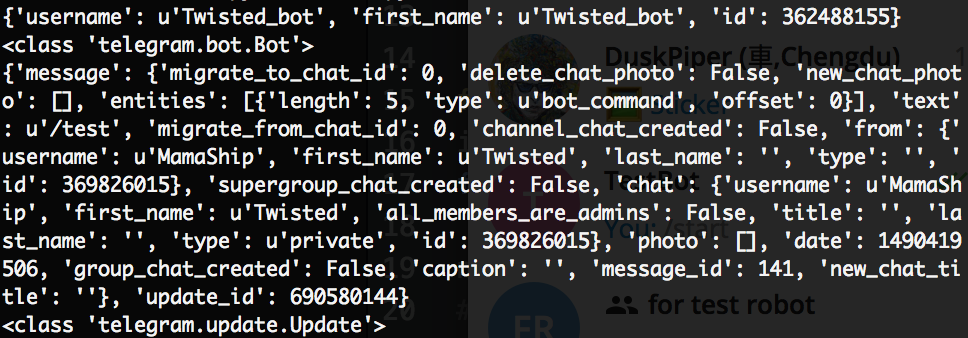
关于它们的属性和相关方法,可以参考官方文档。
python 操作 mysql
主要用到库 MySQLdb
大致是这么个操作方式:
# 打开数据库连接
db = MySQLdb.connect("localhost","testuser","test123","TESTDB" )# 使用cursor()方法获取操作游标
cursor = db.cursor()# 使用execute方法执行SQL语句
cursor.execute("SELECT VERSION()")# 使用 fetchone() 方法获取一条数据库。
data = cursor.fetchone()# 关闭数据库连接
db.close()
具体可以参考这个:python操作mysql数据库
有一点需要注意:执行INSERT这类修改数据库的操作之后,需要用 db.commit() 这句来提交事务,否则 mysql 那边不会真正的插入数据。(关于 autocommit 的探讨参见:Python 的 MySQLdb 模块插入数据失败与 autocommit(自动提交)的关系)
为robot创建一个mysql数据库
mysql很简单,具体过程不表。
创建之后,由于我们robot主要还是要说中文的,所以把数据库的字符集改成utf8:
show variables like 'character%';退出 mysql,去
vim /etc/mysql/my.cnf在各对应字段加入默认字符集设置:
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
character-set-server=utf8
重启服务之后,再进入 mysql,你会看到还是有一点小问题:
mysql> show variables like ‘character%’;
+————————–+—————————-+
| Variable_name | Value |
+————————–+—————————-+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | latin1 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+————————–+—————————-+
8 rows in set (0.01 sec)
我试了试执行:
ALTER DATABASE `Robot` DEFAULT CHARACTER SET utf8;可行。
python的中文支持问题
python有很多方面都需要修改,才能正常处理中文字符串。在文档前加
# -*- coding: utf-8 -*-import sys
reload(sys)
sys.setdefaultencoding('utf-8')可以参考这篇文章:python2.7 查询mysql中文乱码问题
使python在后台运行
这篇文章提供了多种方案:python脚本后台运行
我为了调试方便,使用的是tmux:
1、启动tmux
在终端输入tmux即可启动
2、在tmux中启动程序
直接执行如下命令即可(脚本参考上面的): python test123.py
3、直接关闭ssh终端(比如putty上的关闭按钮)
4、重新ssh上去之后,执行如下命令:
tmux attach
现在可以看到python程序还在正常执行。
来测试我的机器人
Telegram上搜索 @Twisted_bot 来与他对话。
相关代码开源在:https://github.com/MamaShip/TwistedBot