
今年初,有感于微信公众号平台删帖效率,打算写一个自动检查文章是否被删的机器人。
并不想弄成爬虫,只想关注我和小伙伴们所接触的领域里的信息审查状况。就把它设计成了「被动接受观察目标,定期观察和备份文章,检查到文章失效通知登记者」的系统。
设计上几个目标:
> 最好直接工作在微信平台上,这样用户看到可能被删的文章,可以直接传递给机器人观察。
> 程序自身最好是无状态的,这样我可以随时停止/更新/重启它,而不用担心用户端的操作被影响。也就是数据(哪怕临时数据)都存进数据库里,跟程序分离开。
> 只收集最小化的必要信息来完成任务。
> 系统的各个部分做到模块化,做成可独立运行和测试的组件,也方便协同开发和debug。
项目地址:https://github.com/MamaShip/Observer
运行在 Linux 服务器上,程序主体用 python 实现,数据库 MySQL,使用了系统自带的 sendmail 服务。对接微信公众号平台的部分用到了 wechatpy 库,所以是用微信公众号来当机器人。
框架
基于 python 的机器人库有很多,但微信对权限的控制非常严格。开发者实际很难使用个人账号执行机器人操作。我研究下来,基本只有 「微信公众号 + wechatpy」 一个可行且稳定的方案。
> wechatpy 项目地址:https://github.com/wechatpy/wechatpy
> 使用文档:https://wechatpy.readthedocs.io/zh_CN/master/
> 另外,强烈建议从他们提供的 example 仓库入门:https://github.com/wechatpy/wechatpy/tree/master/examples
该方案的一个局限性是,微信对公众号的权限限制依然很强。机器人从设计上就要避开对用户的打扰、信息收集。
例如:大多数微信公众号都不具备直接向特定用户发送消息的功能(有些只能群发,有些每天只有1条群发额度),只能接收用户消息并回复(回复必须在5秒内,否则超时),也就是说机器人基本处于一个「被动触发」的工作状态。设计上要考虑到这个因素。
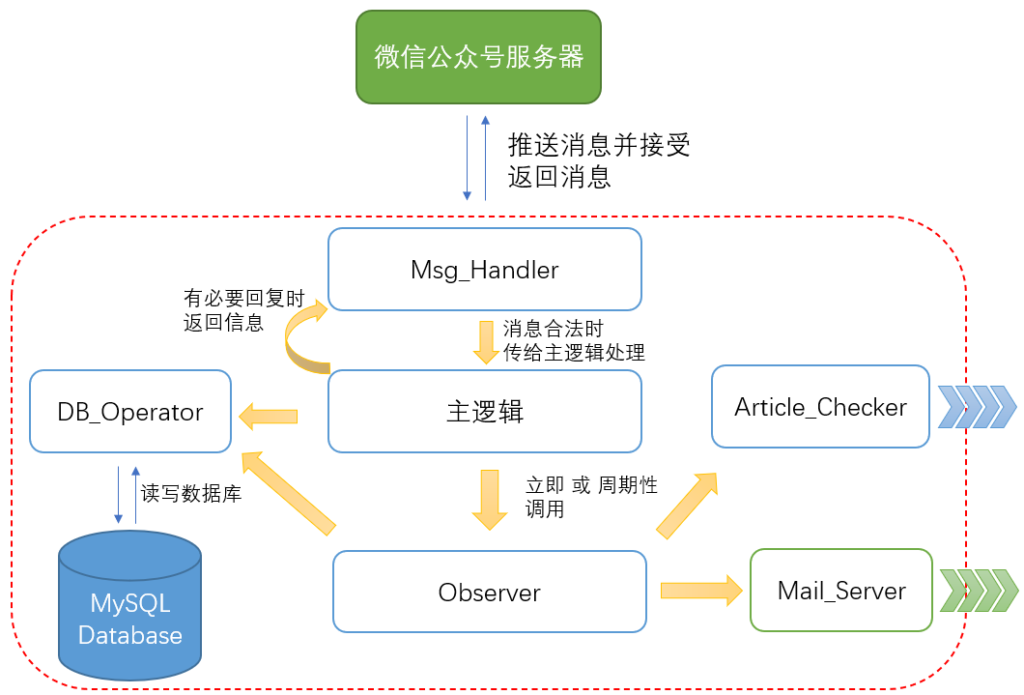
各功能模块规划如上图,红色框内是我的服务器。程序主体都由 python 实现。
由 wechatpy + Flask 承载 Msg_Handler 模块,负责与微信公众号服务器交互。
数据存储使用了我较熟悉的 MySQL。不直接写文件是想靠 MySQL 替我解决多线程带来的并发问题。
其中 Mail_Server 调用了 Linux 本机上安装的 mail 服务。
而 Article_Checker 主要用到了 requests 和 BeautifulSoup 两个库,相当于 python 的爬虫应用。
各模块的界面都是相对固定的,开发前已经定好了接口:https://github.com/MamaShip/Observer/blob/dev/dev_docs/plan.md
因此可以把任务分发给小伙伴协同进行(虽然最后大部分还是我自己做的XD)
从框架图里可以看出:越边缘的模块依赖别人越少。从这些小模块开始做起,有利于围绕它们进行完善的功能测试,使后期整个系统整合起来趋于稳定。
细节实现
微信接口
参照上文提到的 wechatpy 库的 example 仓库,使用了 Flask 作为 Web 框架。
from flask import Flask, request, abort, render_template, escape
from wechatpy import parse_message, create_reply
from wechatpy.utils import check_signature
from wechatpy.exceptions import (
InvalidSignatureException,
InvalidAppIdException,
)
app = Flask(__name__)两个要点:微信公众平台只接受 ip 地址绑定 token;程序必须监听在 80 端口。
因此我们其实是把 Flask 运行在 80 端口上,然后将 "/wx" 的请求转发到我们编写的 wechat() 函数来:
@app.route("/wx", methods=["GET", "POST"])
def wechat():
signature = request.args.get("signature", "")
timestamp = request.args.get("timestamp", "")
nonce = request.args.get("nonce", "")
encrypt_type = request.args.get("encrypt_type", "raw")
msg_signature = request.args.get("msg_signature", "")
try:
check_signature(TOKEN, signature, timestamp, nonce)
except InvalidSignatureException:
abort(403)
if request.method == "GET":
echo_str = request.args.get("echostr", "")
return escape(echo_str)
# POST request
if encrypt_type == "raw":
# plaintext mode
msg = parse_message(request.data)
if msg.type == "text":
reply_text = MAIN_LOGIC.handle_msg(msg)
reply = create_reply(reply_text, msg)
elif msg.type == "event":
reply_text = MAIN_LOGIC.handle_event(msg)
reply = create_reply(reply_text, msg)
else:
reply = create_reply("Sorry, can not handle this for now", msg)
return reply.render()该函数的前一半代码都在做微信要求的校验动作,要返回正确的 echo_str 才能被微信服务器接受。具体参照《微信公众平台开发文档》。
后一半代码则是最普通的 raw 格式(明文)消息处理,可以看到,它根据消息类型调用了主逻辑的相关接口来执行处理,并将返回值发给微信。这些过程大多是使用 wechatpy 提供的现成函数,比较简洁。
if __name__ == "__main__":
app.run("0.0.0.0", 80, debug=False, use_reloader=False)这个消息框架要工作起来,只需在 main 里调用 app.run(),令其监听 80 端口即可。
任务队列
实际编码时,我们发现有些任务是耗时较长的,不能等任务完成再去回复用户消息。
例如邮件发送时,如果附件很大,就无法保证在5s内传完,若超时回复微信平台,用户端会提示「公众号故障,无法提供服务」。
另一个场景是,当用户下命令立即检查文章是否有效,我们的 Article_Checker 并不能立即响应它,因为微信公众号文章有一些反爬虫的特性,如果我们连续执行访问操作,会很容易被识别为爬虫。——代码里最后的实现也是「假装」已经做了检查,实际把任务放入队列中,等 Article_Checker 模块自行判断何时执行下一条。
举例,article_checker.py 内就实现了一个单例的队列 Checker_Queue,主线程的 Observer 模块 put 新观察任务进去,Article_Checker 在自己的独立线程里决定何时 get,并做后续处理:
from queue import Queue, Empty, Full # 标准库提供的Queue是线程安全的
# 一个消息队列用在Observer和Checker之间
# 消息队列的元素是 (文章id, url, 是否下载)
class Checker_Queue:
_instance = None
_lock = Lock()
def __new__(cls, *args, **kwargs):
if not cls._instance:
with cls._lock:
if not cls._instance:
cls._instance = super().__new__(cls)
return cls._instance
def __init__(self, max_size):
self.q = Queue(maxsize=max_size)
def put(self, article_id, url, download, block=True, timeout=None):
if IsValidUrl(url):
try:
self.q.put((article_id, url, download), block=block, timeout=timeout)
except Full:
self.DoPutError()
def get(self, block=True, timeout=None):
try:
(article_id, url, download) = self.q.get(block=block, timeout=timeout)
except Empty:
self.DoGetError()
return None, None, None
else:
return article_id, url, download
def get_queue_size(self):
return self.q.qsize()如果任务更复杂一点,则可以给每个任务元素分别填写回调函数(callback),Article_Checker 执行完任务 call 回调来触发后续动作。
MySQL接口
这部分另开一篇文章记录。
反反爬虫
微信公众号文章,有反爬机制。短时间内同 IP 大量访问,就会被识别和扰乱。
我们遇到过2种情况:
> 文章部分图片加载失败
> 图片链接直接被重定向为蜜罐(一个无限大的永远下载不完的文件)
这也就会导致文章备份不全、备份操作超时的问题。
反爬基本方法参考:
关于反爬虫,看这一篇就够了
应对反爬的主要方法:把一次访问维持在一个会话(session)内,保留它的 cookie,以及 header 内添加 referer 和 UserAgent 让自己看起来更像普通用户的浏览器。
不过所有的反爬操作都应该在部署机器人之前就添加好。如果已经被识别为爬虫了,IP 会上黑名单,要关一阵子才会放出来。
参考资料:
- headers 添加 UserAgent:
- cookie:
- referer:
python 还有个包是 fake_useragent
from fake_useragent import UserAgent
#伪装成浏览器
ua = UserAgent()
headers = {'User-Agent':ua.random} #一般网站伪装成这样也就够了,但是如果想爬图片,图片反盗链的话如下
headers = {'User-Agent':ua.random,'Referer':'这里放入图片的主页面'}
#然后在后续requests中传入header即可账号密码保存
机器人使用的账号需要由程序指定。与之相关的还有密码、密钥等。
若为开源项目,不宜在代码中明文存储。
可以在启动程序时由用户输入提供。也可用配置文件的方式单独存储(使用.gitignore忽略该配置文件,避免被git版本跟踪,导致在互联网暴露)。
我选择将账号密码以环境变量的形式存储在运行bot程序的服务器上。
修改环境变量,编辑:/etc/bash.bashrc
在后面加入:export PSWD="blablabla"
左边是环境变量名,右边是存储的值。
⬆️这是给所有使用 bash 的用户新增环境变量。也可以单独给特定用户设定,具体修改的文件不同,不赘述。
python 程序内读取环境变量的方式是 os 库的 os.getenv 方法:AES_KEY = os.getenv("WECHAT_AES_KEY", "default_value")
第一个参数是欲获取的环境变量名,第二个是没有找到该变量时返回的默认值。
环境变量在sudo之后失效的问题
是因为sudo操作默认重置所有环境变量。如果想要保留,可以在 /etc/sudoers 文件中添加例外:
Defaults env_keep=”…”引号内是指定sudo后保持的环境变量。
若要添加多条例外,像这样:
Defaults env_keep += "http_proxy"
Defaults env_keep += "https_proxy"
Defaults env_keep += "HTTP_PROXY"具体参见这篇文章:http://blog.sina.com.cn/s/blog_4da051a60102uyvg.html
日志记录
使用 python 标准库里的 logging 来记录日志。
在每个模块的头部做如下定义:
import logging
#先声明一个 Logger 对象
logger = logging.getLogger("mysql")
logger.setLevel(level=logging.INFO)
#然后指定其对应的 Handler 为 FileHandler 对象
handler = logging.FileHandler('mysql.log')
#然后 Handler 对象单独指定了 Formatter 对象单独配置输出格式
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler.setFormatter(formatter)
logger.addHandler(handler)之后代码里在需要记日志的地方用 logger 记录即可:
logger.debug("db connection created")
logger.info("fetch no item with cmd:" + query)
logger.warning("commit fail when executing cmd: " + cmd)
logger.warning("> with parameters: " + " ".join(map(str, parameters)))
logger.error("_delete process fail: " + string)
logger.exception("_commit_cmd Error")它们分别对应了不同的日志级别:debug、info、warning、error。
logger.exception 不仅会记录你用参数提供的信息,还会把异常发生时的调用栈也记录下来。(它只能用在捕获异常的 except 语句代码块中)
微信限制
微信服务器在将用户的消息发给公众号的开发者服务器地址(开发者中心处配置)后,微信服务器在五秒内收不到响应会断掉连接,并且重新发起请求,总共重试三次,如果在调试中,发现用户无法收到响应的消息,可以检查是否消息处理超时。关于重试的消息排重,有 msgid 的消息推荐使用 msgid 排重。事件类型消息推荐使用 FromUserName + CreateTime 排重。
微信公众号开发文档内未指明文字消息的长度限制,但我测了下,限制是2048个字节。
由于英文字母和数字都只占1个字节。而汉字要占3~4个字节。所以当消息中存在汉字时,可发送的文字长度将大大减少。
每次版本发布时自动生成 Change Log
使用的工具是 git-chglog
每次发布版本前可以自动生成 change log,类似这样:
https://github.com/git-chglog/example-type-scope-subject/blob/master/CHANGELOG.standard.md
但是对开发者的 commit 格式有要求,具体规范:
Commit Message Format
可以参考 Angular commit message.
发表回复